What is CNN? A 5-Year-Old Guide to Convolutional Neural Network
Originally published on Medium.
A 5 year old kid trying to understand CNN
Okay, that title might be a little bit misleading, because let’s face it no 5 year old will try to find out what a Convolutional Neural Network 🤣. This guide is targeted for beginners in deep learning who want to learn more about Image Processing, but feels pressured when seeing papers and other writing that seems a little bit too hard to understand 😂.
A Gentle Introduction
Artificial Intelligence or AI is a monumental breakthrough that bridges the gap between what humans can do and what machine can do. One of many areas that was affected by the development of AI was Computer Vision. Those advancement created an algorithm for the Computer Vision domain that was known as Convolutional Neural Network or CNN for short.
CNNs, like neural networks, are made up of neurons with learnable weights and biases. Hummm, wait what are neural networks? Wasn’t this guide supposed to teach a 5 year old ?? 😢. Yes, I hate to break it to you, but to understand CNN, you have to know what a neural network is first. You can refer to this reference though 😁. Each neuron in CNN will receive several inputs, takes a weighted sum over them, passes it through an activation function and responds with an output. The whole network has a loss function and all the tips and tricks that we developed for neural networks still apply on CNNs. Okay, that’s enough of the hard part 😊.
So, CNN is basically a deep learning algorithm that can take images as its input and by some process of learning able to differentiate one image from another. This result could be achieved by changing the parameters (learnable weights and biases) of the model itself.
Representation of CNN Architecture
What makes CNN stand out from other classification techniques for classification of images is the total number of pre-processing required for the CNN / ConvNet is much lower as compared to other classification algorithms. Fun fact, the architecture of CNN and the majority of neural networks itself are really similar to the connectivity pattern inside of human brains and was inspired by the Visual Cortex of humans itself.
A few concept about CNN
Okay, if you are still reading this post till this section, you may realize that I was lying to you guys about a guide for a 5 year old 🤣. Truthfully, this post was made for beginners who are scared to learn about CNN and neural networks (not for 5 year olds). Understanding a few concepts about CNN may also open your eyes about how fascinating this neural network is. So without further ado, brace yourself for the concept needed to truly understand CNN 😉
CNN Layer for classification
Image as an input
An image is a matrix of matrix value that indicates the pixel value for the image. One of the main reasons CNN is really good with classification based on image was because CNN is able to capture the Spatial and Temporal dependencies in an image through the application of relevant filters. Remember, the role of the CNN is to reduce the image into a form that is simpler for the algorithm to process, while still retaining the information of the images. Because of this, CNN takes less time to process images than other algorithms, making it one of the best algorithms to use when trying to tackle image problems.
Convolutional Layer
A convolutional layer is a filter (or kernel) in which is an integral component of the layered architecture of the CNN itself. Generally, it refers to the operation applied to the entirety of the inputs (in our case, the image) such that it transforms the information encoded in the pixels into much smaller details. In practice, a kernel is just a smaller-sized matrix from the input size matrix, that consist of real valued entries. Some people say that a picture is worth more than a thousand lectures. So here the representation of the convolutional layer and how it makes information smaller for the neural network to process later on, while still keeping all of the information.
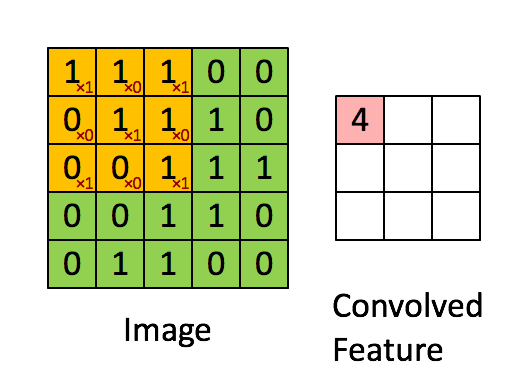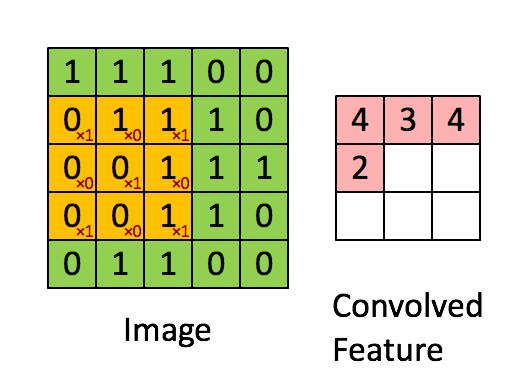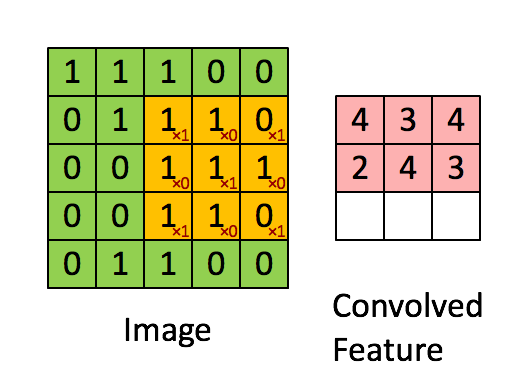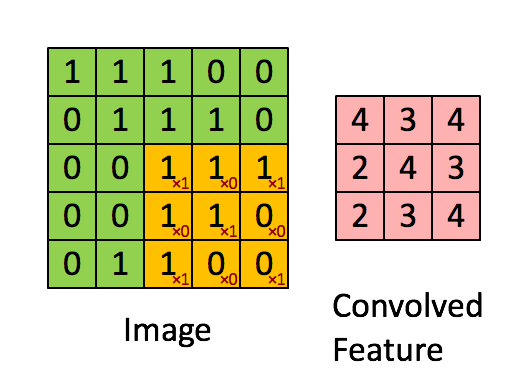
Convolution Process
The Kernel shifts 9 times because of Stride Length = 1 (Non-Strided), every time performing a matrix multiplication operation between K and the portion P of the image over which the kernel is hovering. Remember, this operation only applies on images with 1 (one) channel like grayscale images. In case of images that have multiple channel (like RGB images), Matrix Multiplication is performed between Kn and In stack ([K1, I1]; [K2, I2]; [K3, I3]) and all the results are summed with the bias to give us a squashed one-depth channel Convoluted Feature Output.
Alright, it’s definitely not easy to wrap all of those things in 1 read. Just remember that the objective of the convolutional layer is extract the high-level features such as edges, from the input image.With added layer onto the neural network architecture, the architecture will try to adapts to the High-Level features as well, which make it has the wholesome understanding of images in the dataset, similar to how we would when trying to identify images when we see it.
Pooling Layer
Max Pooling vs Average Pooling
Alright, next we have a pooling layer. What’s the difference between this layer and the previous one tho ? 🤔 Well, the pooling layer is essentially the same as the convolutional layer. It is just another building block of a CNN and is responsible for reducing the spatial size of the Convolved Feature. This layer is useful when we are trying to decrease the computational power required to process the data through dimensionality reduction. Not only that, a pooling layer is also useful when trying to extract dominant features from the inputs. There are two types of pooling layers : Max Pooling and Average Pooling.Max Pooling returns the maximum value from the portion of the image covered by the Kernel. On the other hand, Average Poolingreturns the average of all the valuesfrom the portion of the image covered by the Kernel. Because of the nature of max pooling layer, it also performs as **Noise Suppressant,**as it discards the noisy activations altogether and also performs de-noising along with dimensionality reduction.
The ReLu (Rectified Linear Unit) Layer
So, the Convolutional Layer and the Pooling Layer are the main building blocks of the Convolutional Neural Network. But how do we connect each layer onto each other. Welcoming the ReLu Layer, as it is a layer of an activation function which is responsible for transforming the summed weighted input from the node into the activation of the node or output for that input.
The ReLu layer is not specified only to the Convolutional Neural Network. It is a commonly used layer as an activation function needed in any neural network for transformation in neural networks. As this is a guide to understanding more on the CNN side, I won’t explain much about this layer, but if you want to deep dive about it you can reference it here
Fully Connected Layer
Now, using both the Convolutional Layer and Pooling layer with the addition of ReLu Layer, we can convert our input image into a more suitable form for our Multi-Level Perceptron by flattening the image into a column vector. The flattened vector then fed to a feed-forward neural network and backpropagation applied to every iteration of training. Okay, this sounds a little bit hard to understand for a beginner.
Let me explain it step by step for you to understand what actually happens when training a neural network, which is the basic foundation for CNN. We train neural networks by repeating the learning process for the model then identify whether our model has already found the pattern of the image input and able to differentiate the image input. After each learning process is done, the model will reevaluate it’s parameter on each layer to perform better on the next iteration. This action is called back-propagation and by doing this, the model will perform better and better each time it is trained (might need to watch out for overfitting tho, but this concept is out of this topic).
Over a series of epochs of training, the model is able to distinguish between dominating and certain low-level features in images and classify them using the Softmax Classification technique.
The journey to mastery is good only if you can feel it. Don’t rush it, find your pace and you will succeed 😘
Reference
https://cs.nju.edu.cn/wujx/teaching/15_CNN.pdf
https://cs231n.github.io/convolutional-networks/
https://towardsdatascience.com/simple-introduction-to-convolutional-neural-networks-cdf8d3077bac
https://towardsdatascience.com/deep-dive-into-convolutional-networks-48db75969fdf